· Alex · security · 11 min read
Securing the Software Supply Chain
A history of software supply chain attacks, risk factors and mitigation strategies
Recent History of Software Supply Chain Attacks
Der Spiegel released in 2013 the NSA ANT catalog which hit the cybersecurity industry by storm. Among numerous cool gadgets and tools, a couple of firmware implants (malware) are mentioned. Code names were IRATEMONK (HDD firmware implant) and JETPLOW (Cisco network gear backdoor). You can read more about the catalog here. Why are those relevant? A few months later, a (classified) document released along with Glenn Greenwald’s book No place to Hide, shows how the agencies employees intercepted servers and network equipment being shipped to organizations targeted for surveillance and installed firmware implants before they were delivered. Supply chain attacks were always a concern for cybersecurity people, but that’s when it starting feeling real.
CCleaner
Fast forward to 2017, a blog post by Talos (https://blog.talosintelligence.com/2017/09/avast-distributes-malware.html) describes a supply attack with huge damage potential. CCleaner’s download server was compromised to deliver malware. CCleaner boasted 2 billion downloads at the time, with a growth rate of 5 million users per week.
SolarWinds
A well known and recent supply chain attack is the SolarWinds compromise. It was featured most major news outlets because of its huge reach & impact. This is still investigated at the time of writing this article so full impact is not yet understood. The attackers developed custom malware to run on the company’s build servers and injected additional malware into the product before the code was signed. The exact number of affected entities is unknown, but the compromised update was downloaded around 18.000 times (according to the vendor). In case you’re not familiar with what happened, here’s an easy to digest explanation: https://www.npr.org/2021/04/16/985439655/a-worst-nightmare-cyberattack-the-untold-story-of-the-solarwinds-hack?t=1619272046959. For a more technical approach just google Teardrop, Sunburst, Sunspot or Raindrop malware (the names assigned to the malware discovered in the SolarWinds campaign). Huge Fortune 500 companies and US government entities were affected by this hack, which wasn’t without its consequences (https://www.wired.com/story/us-russia-sanctions-solarwinds-svr/). Due to the nature of the compromise and attacker skill level, it would be very difficult to detect this in the software supply chain. If the build environments are hacked, attackers can tamper with every check. Thus the malware was detected long after it ended up in client installations, when it actually started to exfiltrate data.
”Novel” attack: Dependency Confusion
The discussed attacks are all high complexity and performed by nation states, so they might not be in your Threat Model. Recently, a security researcher demonstrated again the impact of supply chain issues, this time with a way simpler attack. He hacked 35 tech firms (including Microsoft, Apple, Paypal and other big names) with an attack that leveraged a design flaw in some package managers called dependency confusion.
The exploit
The exploit consisted in uploading backdoored packages to open source repositories (like PyPI, npm and RubyGems) using internal package names used by select companies. These packages were distributed down-stream and included into software products by the affected companies. The build process fetched the packages from the public repos instead of getting them from the company’s private repo. In the process, the researcher landed over $130,000 in bug bounties. Read more: https://www.bleepingcomputer.com/news/security/researcher-hacks-over-35-tech-firms-in-novel-supply-chain-attack/.
Having a Bug Bounty program doesn’t mean everything is allowed
Not everyone welcomed his efforts. Dustin Ingram, Director of Python Software Foundation and a Google developer mentioned: “Ultimately if you are interested in protecting users from this kind of attack, there are better ways to do it that protect the entire ecosystem, not just a specific set of organizations with bug bounties” (source https://github.com/pypa/pypi-support/issues/526). Being both a security researcher and a developer, I can’t help but sympathize with Dustin. Volunteers handling open-source projects have better things to do. And what about the people that were exploited? What was going through the mind of the Engineer that got that alert? Imagine checking a failed build and discovering some weird dependency. Even if those companies had a Bug Bounty program, it’s likely that not everyone expected that “test”. Having worked in companies that deliver software with tight schedules, I would only imagine the stress it caused.
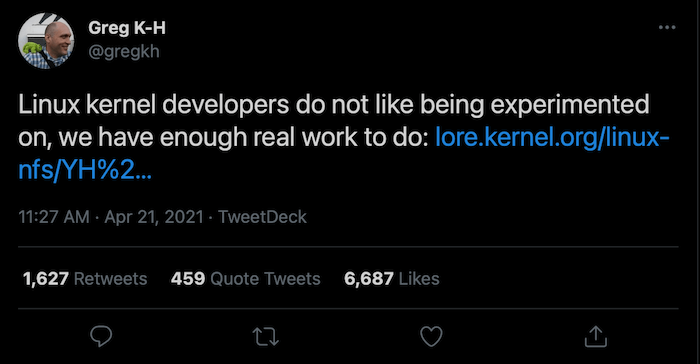
UMN vs Linux Kernel developers
Another example from 2020: someone from The University of Minnesota submitted “fake patches” to the Linux kernel repos. The goal was to prove that one can “slip” security vulnerabilities with the pretext of an improvement or fix without others noticing. While one could consider the attempt as a “penetration test” of the code review process, doing this on open-source, rapidly released software used by millions has its issues and ethical considerations. In 2020 they released a paper (ironically called “On the Feasibility of Stealthily Introducing Vulnerabilities in Open-Source Software via Hypocrite Commits”) it which they “safely demonstrate[d] that it is practical for a malicious committer to introduce use-after-free bugs”.
Unsurprisingly, the Linux kernel team wasn’t pleased with being part of their experiment. By comparison, in a professional penetration test, permission to do these kind of things is always requested and negotiated. If even allowed at all. Audits on production or live systems carry the risk of causing downtime and financial losses, hence they are always tightly scoped. Recently (April 2021), a doctoral student from the same research group submitted fake patches (once more). As expected, this wasn’t received well and for good reason.
Dev talks
“You, and your group, have publicly admitted to sending known-buggy patches to see how the kernel community would react to them, and published a paper based on that work.”
And:
“Because of this, I will now have to ban all future contributions from your University and rip out your previous contributions as they were obviously submitted in bad-faith with the intent to cause problems.”
What do you think? Are the kernel developers overreacting? Should this be part of the life of an OSS software developer? I think that while their study did bring a valid contribution to the cybersecurity industry (and people will use as a future reference), it was has some unethical aspects. A point of discussion is that the student argued that the “fake patches” were the result of running a custom static scanner:
“These patches were sent as part of a new static analyzer that I wrote and it’s sensitivity is obviously not great”.
The dev was skeptical:
“They obviously were _NOT_ created by a static analysis tool that is of any intelligence, as they all are the result of totally different patterns, and all of which are obviously not even fixing anything at all.
Supposing the student isn’t lying and the patch is generated by a tool, why would you submit it without actually checking it? The actual code is useless. So even if this would be an automatically generated thing, hence noisy/low quality, it would still be a submission in bad faith. There are better methods of researching software supply chain security without wasting other people’s time.
Supply Chain & Software Development
The benefits of open source software are well known and using such software as building blocks is very common these days. And it makes sense to reuse code that others developed and tested that serves a certain purpose. Why reinvent the wheel, right? Since modern software is built by glueing together numerous third-party and open source components, with all those benefits, you also take on the responsibility for the code you didn’t write.
Software Composition Analysis is used to inventory these components and mitigate risks created by them. SCA is a limited subset of Component Analysis in the Cyber Supply Risk Management framework (https://csrc.nist.gov/projects/supply-chain-risk-management).
Risk factors
As most things in security, we start with inventory. Do you know what software you’re running? You must have an accurate inventory of all the 3rd party components used in the enterprise as it’s critical to risk identification. Various tools exist to handle this like dependency management solutions or Software Bill-of-Materials (SBOM). After knowing what we have, we have to consider (in no particular order):
Component age
- old or outdated technologies.
Using outdated components
- new releases of active components may improve quality or performance. Using End-Of-Life or End-Of-Support software comes with it’s risks. Semantic versioning usually means that you can safely upgrade across minor versions without worrying of breaking changes (for example 1.1.0 -> 1.1.1). Upgrading the major version (1.0.0 -> 2.0.0) implies incompatible API changes, so it requires extensive work and testing.
Using components with known vulnerabilities
- can create a huge gap in your defense. SCA tools help by gathering CVEs metadata from multiple intelligence sources. They use that to see if the scanned components have known security vulnerabilities. But using such a component in your code doesn’t always mean that your product is vulnerable. Depending on the type of vulnerability, it isn’t always trivial to identify that. Developers familiar with the apps should figure it out quickly though.
Component type & function
- identifying these for all components might reveal certain patterns, like using several components that have the same functionality. This happens with frameworks, parsers (like XML parsers), loggers, etc. Minimizing risk is done by reducing the number of components in use. For example, using a Base64 encoding library when the programming language offers this natively. Or using a util package like Apache Commons (Java) while adding another dependency that fulfils a function already integrated in Apache Commons. Code will need to be refactored to remove those extra dependencies, but it will improve maintainability & reduce attack surface.
Number of components
- is also a big factor (and it’s related to the previous idea). Each new component added to the application increases operational costs as you have to maintain it. The more you have, the harder they are to manage in today’s Agile context. So think hard before adding a new dependency to your project.
Repository trust
- All those open-source components are hosted in public central repositories. This has its own risks like: typosquatting, organization/group abuse or Cross Build Injection (XBI). XBI is abusing dependency resolution schemes and/or weak infrastructure controls to inject malicious components instead of safe/original ones. Which is what the security researcher mentioned earlier did (thus not really a “new attack”). Code-signing is a great mitigation, but not all public repos make use of it. Having private repos helps, but comes with the responsibility of tracing the origin of the component. So you need to make sure that each component has available public code. And that the compiled components matches code signatures. Why is this a problem? Unfortunately, there are developers that are willingly adding library in binary/compiled form to their software.
Licensing & transitive dependencies
- license management and issues introduced by the dependencies of your dependencies
Software Bill of Materials (SBOM)
A Software Bill of Materials is similar to a cook-book containing all the ingredients of an application. According to the OWASP Software Component Verification Standard (https://owasp-scvs.gitbook.io/scvs/v2-software-bill-of-materials):
“Automatically creating an accurate SBOM in the build pipeline is one indicator of mature development processes”.
Creating and verifying SBOMs can help prevent a series of supply chain attacks. Of course, if the build infrastructure is compromised, it doesn’t help much. With an SBOM one can achieve “software transparency”. There are several standards out there (CycloneDX, SPDX, SWID), each with their own use-cases.
Here are the Level 1 requirements of the OWASP SCVS standard:
- 2.1 Generate a machine readable SBOM
- 2.3 SBOM must have an unique id
- 2.7 SBOM must have a timestamp
- 2.8 SBOM is analyzed for risk
- 2.9 SBOM contains a complete and accurate inventory of all components the SBOM describes
- 2.12 Component identifiers are derived from their native ecosystems (if applicable)
- 2.14 Components defined in SBOM have accurate license information
That seems reasonable, right? A good compromise between required effort and results, with more effort required on the analysis part.
Securing the build environment
Today’s software build pipeline may consist of source code & package repositories, continuous integration, delivery processes, testing/auditing procedures and infrastructure. When things run “as a service”, you offload some of your risk to those providers, but at the same time you open yourself to other risks. Each system or step of the pipeline is a potential entry-point to compromising the software supply chain. DevOps / DevSecOps teams have to work with InfoSec & Product Security to secure those systems & services. Automation, proper restrictions, traceability & documentation are key success factors. Host & container security, IAM, secret management and logging are just a few areas that need to be considered. A SBOM is valid as long as the system that is generating it is not compromised itself. As seen in the SolarWinds breach, if the build system is compromised it’s very hard to notice when something goes wrong. Taking a defense in depth approach can help. But ultimately, you’re as strong as your weakest link when facing a motivated attacker.
Securing Software Supply Chain
There is no easy solution to defend against software supply chain attacks. Considering the “shift left” industry approach to writing secure code, Software Engineers must think more about the integrity of their software at each step (requirements -> delivery) and ways to diminish risk for their customers. But they also have to work with DevOps and the security team to have as many layers of security defenses as possible.
Securing the Software Supply Chain: more marathon than sprint
As always, security isn’t a one time thing, but a continuos effort to stay on top of emerging threats. Make sure to perform regular audits of your systems to stay up to date on security best practices and avoid being in the press for the wrong reasons.
About the Author:
Application Security Engineer and Red-Teamer. Over 15 years of experience in Application Security, Software Engineering and Offensive Security. OSCE3 & OSCP Certified. CTF nerd.