· Alex · security · 4 min read
Bypassing Phishing Filters with Quoted-Printable - ?utf-8?
Using encoding to bypass phishing scanners
Bypassing Phishing Filters
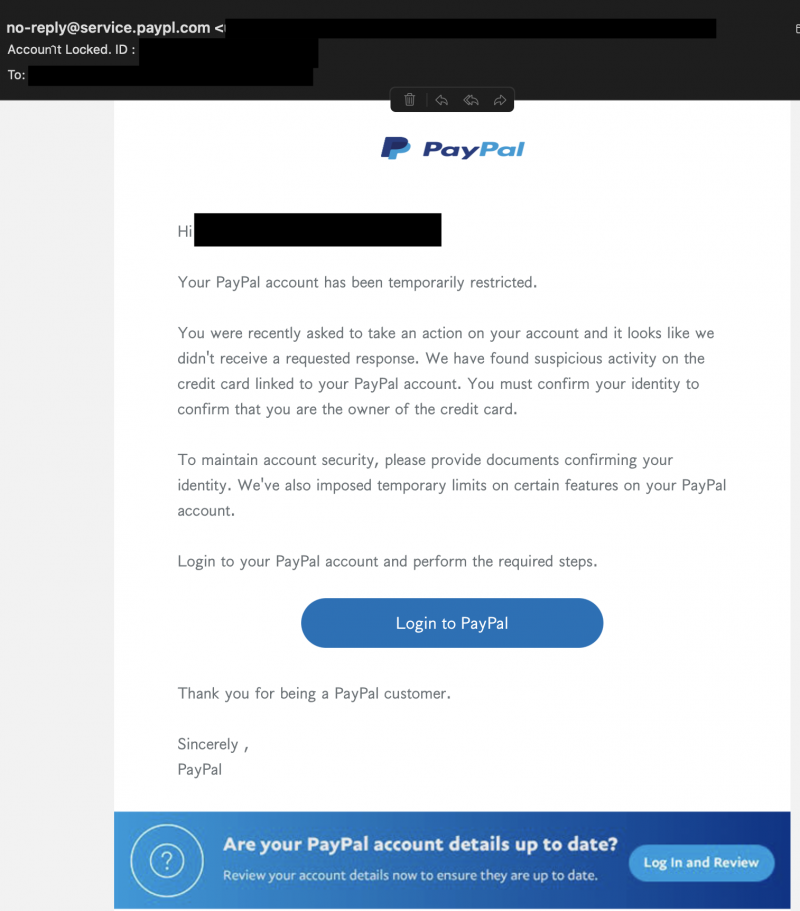
While going through my inbox, a particular phishing email peeked my interest. I usually just mark similar emails as spam and move on with my life. Usually, they contain weird characters or other tell tale signs, from bad spelling or use of punctuation to various methods of creating a sense of urgency. Not sure what made me look at this one. It might be because recently there isn’t much spam hitting my inbox. Spam and phishing filters do work, but often phishers find tricks to bypass them.
The obvious giveaway there is the email domain and a few language errors, but otherwise the phish looks decent. Looking at the raw email source, I saw some encoded text I didn’t recognize. Phishers use encoding or obfuscation to bypass automated tools, relying on the fact that email clients perform certain types of decoding automatically (like HTML encoding). As an example, here is the “From:” email header:
From: =?UTF-8?B?bs2Pb+GetS1yZeKBrXDigI5seUBz4oGvZeKBqnJ24oGtaWPiga5lLnDhnrRh4oGseeKBr3BsLuKAjmPigIxvbQ==?=A few google searches later, I found a RFC from 1996 that defines a protocol for handling MIME messages containing non ASCII characters. Section 2 of RFC 2047 mentions how to interpret this encoding:
encoded-word = “=?” charset “?” encoding “?” encoded-text “?=”So:
- =? -> is a prefix
- ? -> a delimiter
- UTF-8 -> charset
- B -> stands for Base64. The other type of encoding we can have here is “Q” that stands for “Quoted-Printable”. We’ll talk about this later in this article.
- bs2Pb+GetS1yZeKBrXDigI5seUBz4oGvZeKBqnJ24oGtaWPiga5lLnDhnrRh4oGseeKBr3BsLuKAjmPigIxvbQ== -> payload
- ?= -> the suffix
Know that we know how it works, we can try to decode the Base64 using CyberChef or your favorite tool. CyberChef showed some funky characters so I decided to do it locally and dump the hex bytes:
echo 'bs2Pb+GetS1yZeKBrXDigI5seUBz4oGvZeKBqnJ24oGtaWPiga5lLnDhnrRh4oGseeKBr3BsLuKAjmPigIxvbQ==' | base64 -d | xxd
00000000: 6ecd 8f6f e19e b52d 7265 e281 ad70 e280 n..o...-re...p..
00000010: 8e6c 7940 73e2 81af 65e2 81aa 7276 e281 [email protected]..
00000020: ad69 63e2 81ae 652e 70e1 9eb4 61e2 81ac .ic...e.p...a...
00000030: 79e2 81af 706c 2ee2 808e 63e2 808c 6f6d y...pl....c...omNotice the extra bytes (’.’). For comparison, here’s how the same text would look in hex if it were to use ASCII characters only:
echo "[email protected]" | xxd
00000000: 6e6f 2d72 6570 6c79 4073 6572 7669 6365 no-reply@service
00000010: 2e70 6179 706c 2e63 6f6d 0a .paypl.com.However the email client displays these characters just fine:
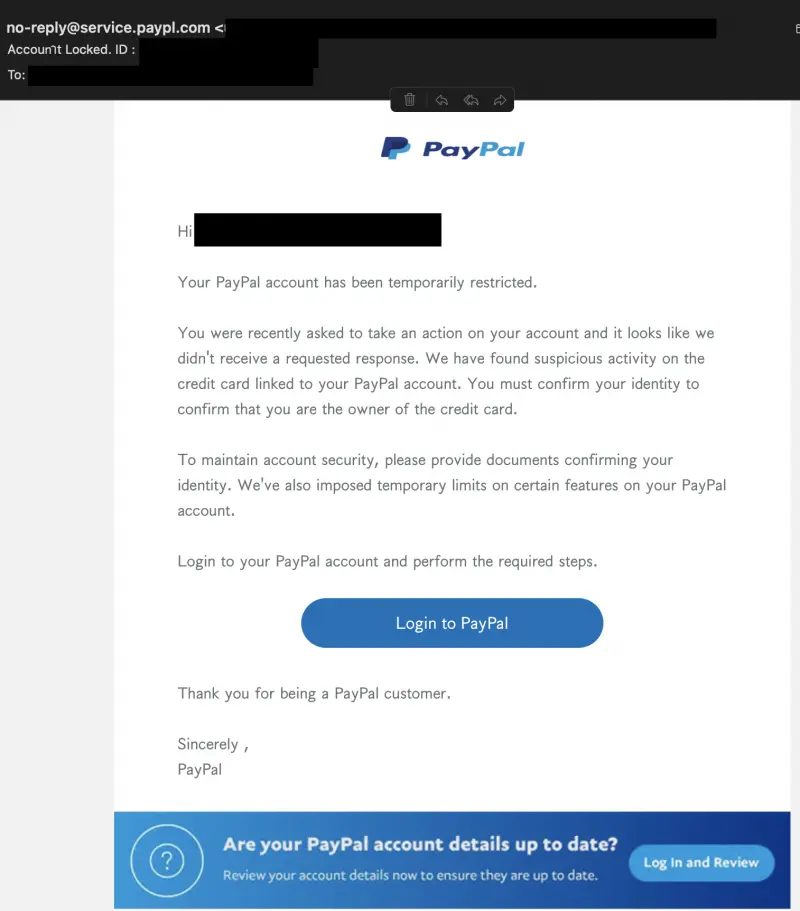
Same thing for the “Subject:” header:
_Subject: =?UTF-8?B?QeKBrmNjwq1vdeKBrW7hnrV0IExv4oGuY82Pa2XCrWQuIElEIDogTllPRlYtTVFaQ1ZNTA==?=_Moving on to the actual content of the email, we encounter the same “Quoted-Printable” encoding.
How to Tell If an Email Uses “Quoted-Printable” Encoding?
Easy. Just look for the email header:
_Content-Transfer-Encoding: quoted-printable._How Does “Quoted-Printable” Encoding Look Like?
Here’s a sample from the raw email source:
=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=
=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=
=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=
=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=
=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=
=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=
=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=
=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=E2=80=8C=F0=
=9D=96=A7=F0=9D=97=82By decoding the above in CyberChef, we get:
decode quoted printable](~/assets/images/decode_quoted_printable.png)
So it’s just “Hi” prepended with a bunch of invisible spaces. If we lookup that byte sequence (E2 80 8C), this turns up:
U+200C e2 80 8c ZERO WIDTH NON-JOINERThe actual phishing link takes the target through a series of HTTP redirects, abusing URL shorteners from reputable companies (Twitter & LinkedIn) and 1 or more hacked websites until landing on the actual phishing page.
Here is a poorly coded script to decode the raw email. It might miss some lines, but it worked for my needs (inspired from here).
import quopri
from io import BytesIO
import base64
import re
import sys
def decode_w(encoded):
encoded_word_regex = r'=\?{1}(.+)\?{1}([B|Q])\?{1}(.+)\?{1}='
match = re.match(encoded_word_regex, encoded)
if match:
charset, encoding, encoded_text = match.groups()
if encoding == 'B':
byte_string = base64.b64decode(encoded_text + f'==')
elif encoding == 'Q':
byte_string = quopri.decodestring(encoded_text)
return byte_string.decode(charset)
else:
return encoded
output_f = BytesIO()
f = open(sys.argv[1], "r")
quopri.decode(f, output_f)
output = output_f.getvalue().decode()
output_lines = output.split('\n')
for l in output_lines:
words = l.split(' ')
line = ''
for w in words:
line+=decode_w(w)
print(line)About the Author:
Application Security Engineer and Red-Teamer. Over 15 years of experience in Application Security, Software Engineering and Offensive Security. OSCE3 & OSCP Certified. CTF nerd.